
計算機科学
「ふつうのコンピュータ」の限界を超えるために

世の中にはいろいろなコンピュータがありますが、 大半は大きく「フォン・ノイマン型」とか、 あるいはもうすこし詳細に「ストアード・プログラム方式」 と呼ばれる方式で、
- 固定された機能のハードウェアが
- メモリに書かれたプログラムに従って動作し
- プログラムを書き換えることでさまざまな機能を実現する
という仕組みです。電気釜や携帯電話や自動車に載っているような、 超小型のコンピュータから、パソコンやスーパーコンピュータまで、 基本的に同じ方式です。この方式の素晴らしいところは、 形のない「プログラム (あるいは、ソフトウェア)」 によって、同じハードウェアでもさまざまな機能を実現できる、 という点にあります。人類が発明してきたいろいろな道具の中で、 もっとも柔軟で、さらに人間の創造力を刺激する存在といえるでしょう。
ところで、「よいコンピュータ」の基本的な要件には、
- 消費電力が少ない
- 時間あたりにできる計算の量が多い
ということができます。つまり、ある計算処理を行う場合に、 それを完了するのにどれだけの電力と時間が必要か、ということです。 しかし、ここまでで説明してきたような「ふつうのコンピュータ」には、 この点において厳しい制約を抱えています。それは、 この方式のコンピュータでは
- プログラムの次の命令をメモリからとってくる
- (必要なら) その処理に必要なデータをメモリからとってくる
- 命令を実行して計算を行う
- (必要なら) その結果をメモリに書き込む
という一連の手続きを繰り返して処理を行う点にあります。 プログラムもデータもメモリに置かれている以上、 メモリへのアクセス能力が、 一定時間にできる計算の量を制約してしまうことは明らかです。 さらにコンピュータのひとつの命令というのは、 非常に単純な処理だけを行うものなので、 性能を上げるためには基本的には、回路の動作周波数を上げて、 一秒あたりに実行する命令の数を増やさなければなりません。 しかし、動作周波数と消費電力は比例してしまいます。 過去数十年にわたるコンピュータに関連する技術の進歩は、 メモリへのアクセスをいかに高速化し、 ひとつひとつの命令の実行をどれだけ効率よく行うか、 の2点に集約できる、ともいえます。
Reconfigurable/Custom Computing
メモリへのアクセスが性能の上限をきめてしまう、 いわゆる「フォン・ノイマン・ボトルネック」を回避するために、 さまざまな方法が考えられてきました。そのひとつが、 解く問題はハードウェア的に固定されていて、 メモリにはデータだけが置かれる、という専用計算機のアプローチです。 これなら、 メモリのアクセス能力をすべてデータのアクセスに割り当てて、 最大限に利用することができますし、 ソフトウェアによって1ステップずつ問題を解くのではなく、 専用のハードウェアによる強力な処理能力も実現することができます。

専用 (Custom) 計算機は強力ですが、その名前の通り、 決まった問題を解くための専用の機械ですから、 強力な性能と引き替えに次のような問題をもっています。
- 設計時の想定と違う内容の計算処理をすることができない
- 専用の回路の開発に時間とコストが必要
したがって、専用計算機は、 その開発のコストに見合った性能が得られ、またそれが必要とされる、 という条件が揃わないと現実的な選択肢ではありません。
一方、LSI の世界では、1985年にはじめて商用化された FPGA (Field-Programmable Gate Array) などの、「再構成 (Reconfigurable) 型」 とよばれるデバイスの開発が続けられています。 これらのデバイスは、"Field-Programmable" や「再構成」という言葉の通り、工場ではなく現場で、 LSI 上の論理回路を変更することができます。
コンピュータのプログラムを書き換えるように、 論理回路そのものを変更できるため、 現在ではこのような LSI が、製品サイクルの速い家電製品や、 自動車などに広く用いられるようになってきています。これは、 開発期間の早い時点で基板の設計を行い、 そのあとでその上のチップの設計を煮詰めることができる、とか、 ゼロから LSI を作るよりもずっと安価である、といった理由からです。
FPGA のようなデバイスを使う場合、デバイスそのものは汎用品なので、 専用の LSI を作るよりはずっと安価ですが、当然、 専用 LSI よりは動作速度が遅いとか、 あまり大きな回路を載せることができないとか、 そういったデメリットはあります。 しかし、これを使えば、事実上の専用計算機を作ることが可能です。 この点に着目した研究グループは数多くあり、 FPGA の草創期からさまざまな再構成型の計算機 (Reconfigurable Computer) が作られてきました。これらは、 文字列処理などの整数演算処理において、 非常に強力な処理能力と低消費電力を実現できることを実証してきました。
しかし、「あまり大きな回路を載せることができない」という制約は重く、 科学技術計算で用いられるさまざまな実数計算は長い間、 再構成型の計算機のターゲットの外側にありました。 私たちの研究グループでは、 最近の大きな FPGA を用いて、 科学技術計算向けの計算エンジンを実現するための手法について研究しています。
数値計算流体力学のアクセラレータ
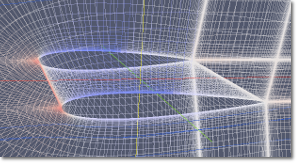
Computational Fluid Dynamics (CFD) と呼ばれる手法は、 液体や気体などの流体の挙動をコンピュータを使って再現するもので、 自動車や航空機のまわり、 あるいはエンジンの中でどのような現象が起こるのかを、 シミュレーションするものです。風洞実験などで、 実際に試すことも重要ですが、コンピュータを使うことで、 実験するのは難しい条件の再現を行うこともできます。
では、コンピュータを使えば簡単にどんな条件でも試せるのかというと、 そう簡単ではありません。たとえば、 右の図は飛行機の翼の一部をモデリングしたもので、 その周辺の圧力分布を計算したものです (左側が前方で、 翼の前縁で圧力が高く、下面より上面のほうが圧力が低いので、 揚力が発生していることがわかります)。 シミュレーションをする場合には、 この図のように空間を数多くの格子点に分割して、 それぞれの小さい領域での現象をコンピュータで解きます。
したがって、 シミュレーションの対象となる物体が旅客機のように大きかったり、 ジェットエンジンの内部のように複雑な形状であったりすると、 格子点数が非常に大きくなり、シミュレーションには膨大な時間が必要です。 これを解決するために、従来からベクトル計算機や並列計算機といった、 いわゆるスーパーコンピュータが使用されてきましたが、 それでも計算能力は充分であるとはいえませんし、 シミュレーション技術の進展に伴って、 計算モデルはますます複雑化しています。
ちょっと前の仕事: システム生物学

FPGA を使った科学技術計算ではじめに取り組んだ研究は、 「システム生物学」とよばれる分野で、 細胞の中で起きている一連の化学反応をシミュレーションする、 というものでした。当時はちょうど、大容量の FPGA の出始めの頃で、 FPGA で浮動小数点演算を使ってシミュレーション、というのは、 まだ新しいテーマだったのではないかと思います。 当時はまだ大きな FPGA とメモリを積んだ安価な評価ボードが手に入らず、 修士論文そっちのけで回路図をひいて、 ボードを作るところからのスタートでした。 いまは各社からいろいろなボードが出ていて、 そのまま研究に使えて、いい時代になったなあ... と思います。
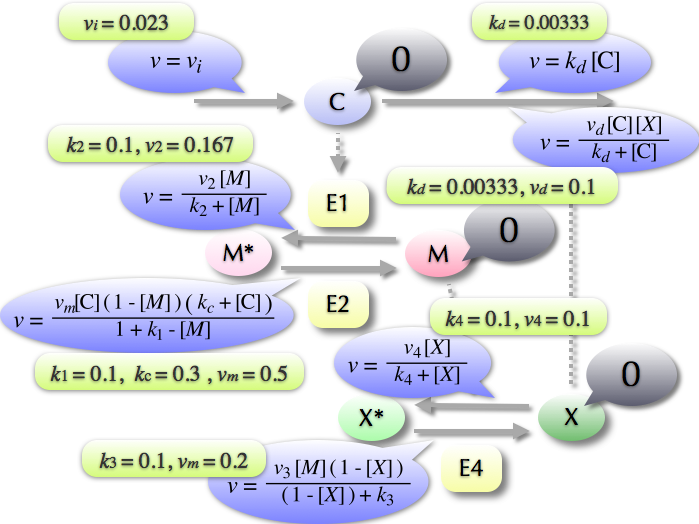
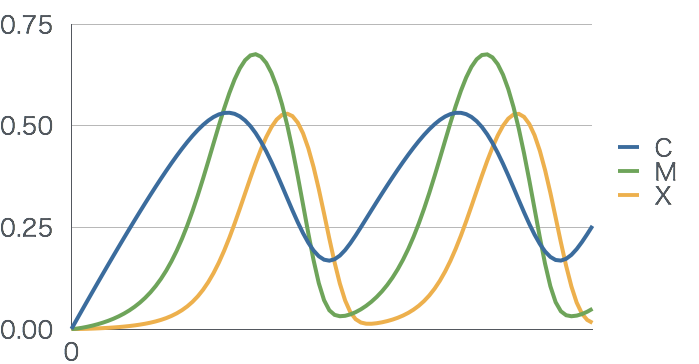
細胞、というのは途方もなく複雑なシステムで、 KEGG Atlas などをご覧いたければわかるのですが、 ものすごい数の化学反応が順序よく起こり、生命活動を形成しています。 シミュレーションでは、これらの化学反応によって、 どの時点でどの物質がどれくらいあるか、 というのを時系列を追って計算していきます。右図のように、 物質の間には反応をあらわす矢印があり、 その反応にはそれぞれ反応速度をモデル化した方程式があり、 物質の初期濃度や反応速度のいろいろのパラメータを入れてやると、 ようやくモデルができ、 これをシミュレーションすることで右下のようなグラフが得られます。
しかし、ここではいくつかやっかいな問題があります。 細胞がちょっとしたストレスで簡単に死んでしまうことは容易に想像できると思いますが、 そもそも中の状態に影響を与えずに物質の濃度その他を観測することは、 非常に困難です。したがって右図に示したようなパラメータのほとんどは、 実験による測定が困難か不可能であり、 実験でわかった事実と整合性がとれるようなパラメータのセットを導出することが必要で、 そこに生物学的な意義があるともいえます。したがって、 パラメータを変化させながらコンピュータを使って何度も何度も計算を繰り返し、 最適な値を発見することがひとつの大きな目標になります。 モデルが小さければ、 一回のシミュレーションにはさほど時間がかかりませんが、 パラメータ探索には大変な時間がかかります。そこで、 ふつうのデスクトップのコンピュータに組み込んだFPGAボードでシミュレーションを行うことで、大幅な高速化を実現するようなシステムにしたいと考えました。
次に、ハードウェアで計算するという観点から考えると、 流体計算ではすべての格子点について同じ方程式を解けばよいのに対し、 こちらの問題では反応の種類ごとに違った反応速度式があります。 したがって、ハードウェアでこれを解くためには、 それぞれの反応速度式に対応した回路を用意しなければなりません。 FPGA の回路の容量の制約はありますが、 再構成型アーキテクチャの特徴を活かして、 モデルごとに最適な回路を自動的に構成する手法の開発を行いました。
いまではふつうのコンピュータがすっかり速くなってしまったのですが、 当時の Intel の CPU と比べると、数倍から数十倍の速度を達成しました。 消費電力は CPU よりずっと小さいので、 今後もこのような手法は有効と考え、いまの研究テーマにつながっています。